
DrissionPage一个基于Python的网页自动化工具
大约 2 分钟
爬虫自动化工具
爬虫作为计算机技术重要的组成部分,虽然大多数人平时接触不到、但却在各种各样的应用软件下游做着技术和数据支持。尤其在大模型爆发增长的现在,大量的爬虫软件在各大 电商平台、教育平台、医疗平台、法律平台、整备制造平台等 24 小时不间断的运行,为大模型的训练提供源数据。
除了大规模爬虫业务,还有很多小需求的采集,他们不需要破解、不需要大规模工程化开发。
我常用的这款工具,如果你要采集小规模数据源、或者做一些羊毛的业务,再配合上指纹浏览器非常丝滑,关键对新手非常友好、还是基于 python 的。

DrissionPage 是一个基于 Python 的网页自动化工具。既能控制浏览器,也能收发数据包,还能把两者合而为一。可兼顾浏览器自动化的便利性和 requests 的高效率。功能强大,语法简洁优雅,代码量少,对新手友好。
不论是动态的 Javascript 渲染的动态网页内容,或是静态网页数据,DrissionPage 都能轻松搞定。下面我演示几个常见例子。
示例
抓取数据包
from DrissionPage import ChromiumPage
from TimePinner import Pinner
from pprint import pprint
page = ChromiumPage()
page.listen.start('api/getkeydata') # 指定要监听的目标,然后启动监听
pinner = Pinner(True, False)
page.get('http://www.hao123.com/') # 打开这个网站
packet = page.listen.wait() # 等着拿到数据包
pprint(packet.response.body) # 把数据包里的内容打印出来
pinner.pin('用时', True)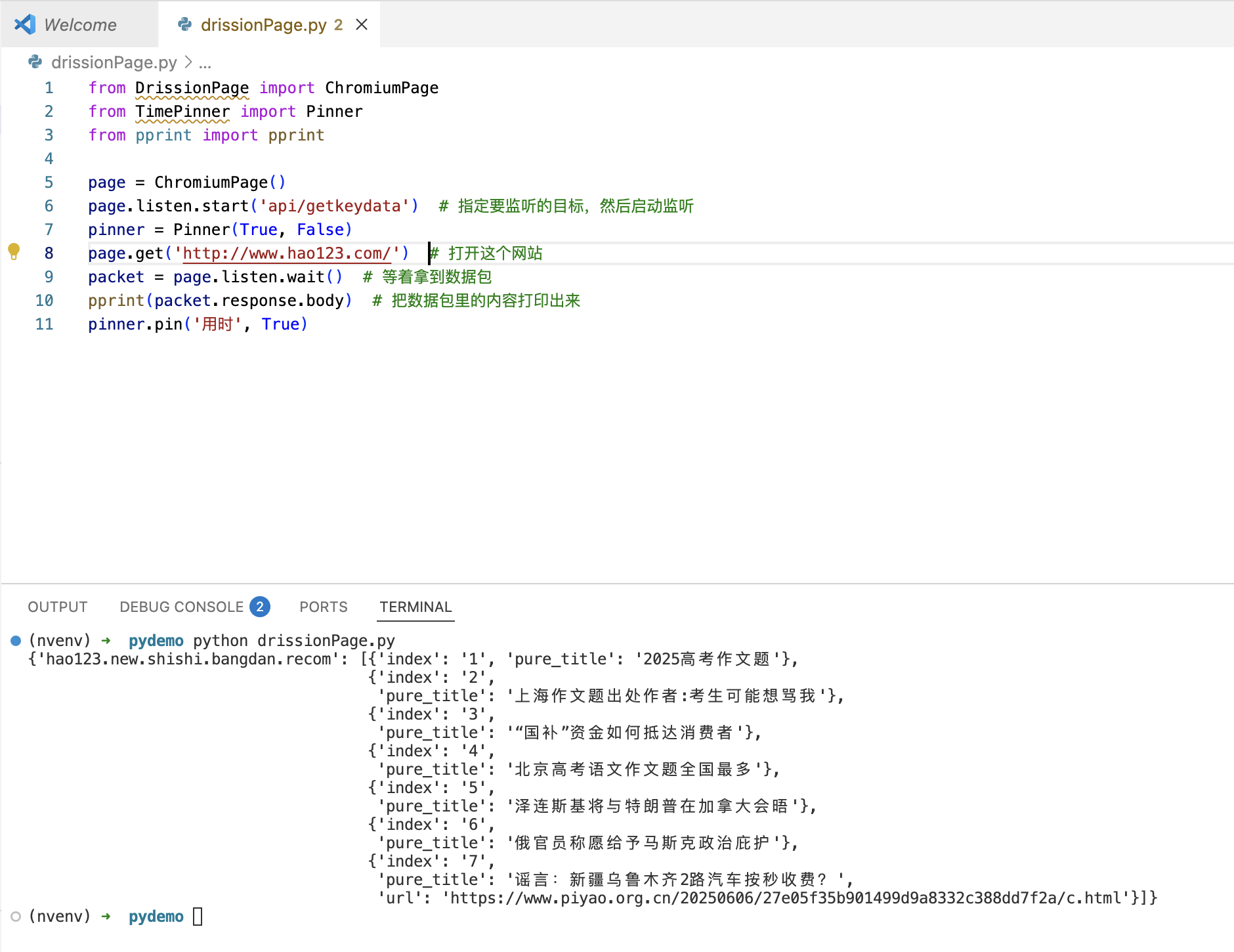
它将监听到的数据包打印出来。
操作浏览器
from DrissionPage import ChromiumPage
page = ChromiumPage()
page.get('https://gitee.com/login') # 打开登录页面
# 找到账号输入框
user_login = page.ele('#user_login')
user_login.input('JavaPub') # 输入账号
# 找到密码输入框
user_password = page.ele('#user_password')
user_password.input('javaub.is.password') # 输入密码
# 找到登录按钮并点击
login_button = page.ele('@value=登 录')
# 点击动作
# login_button.click()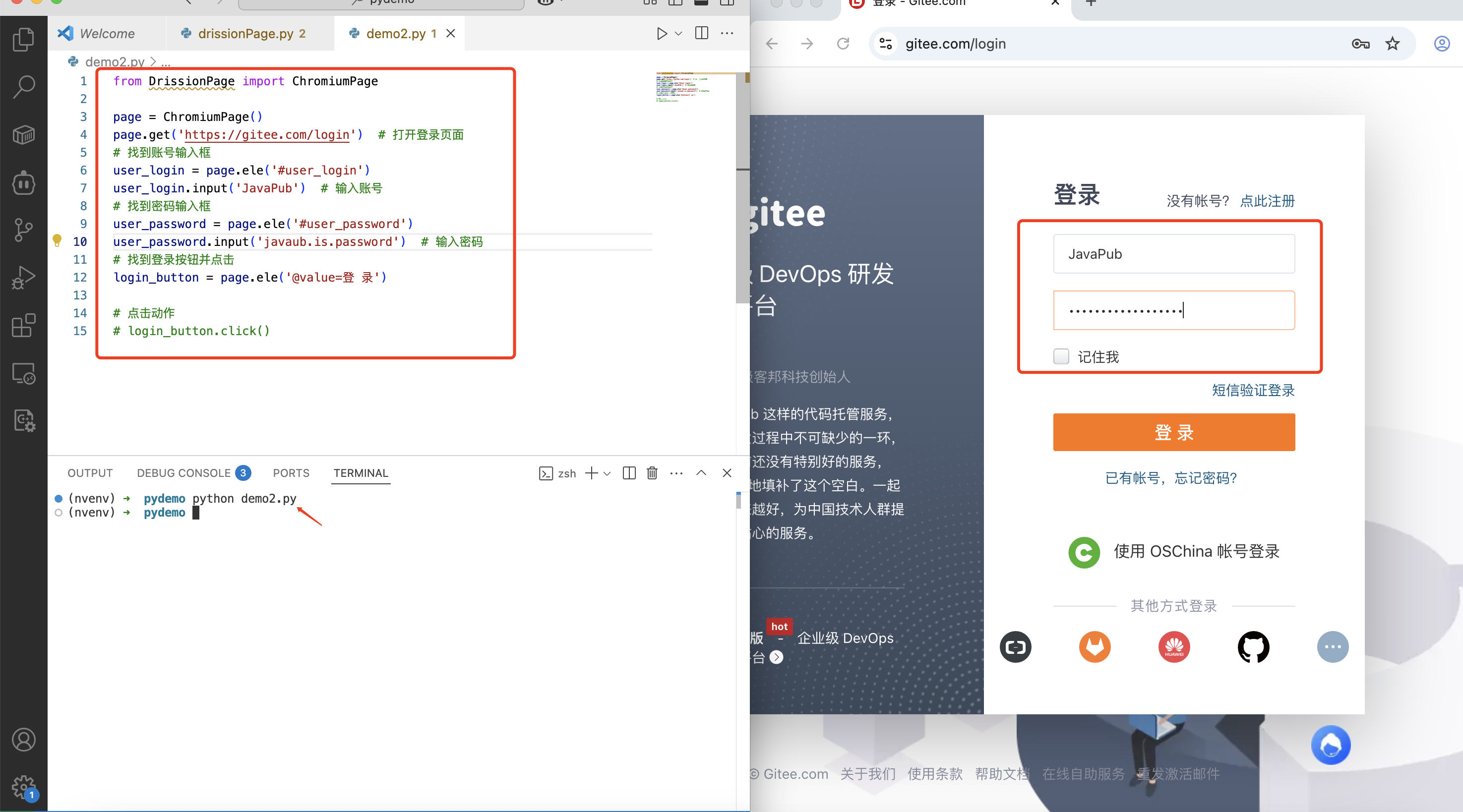
DrissionPage 是个功能强大的且使用方便的 Python 开源工具,通过整合 Selenium 和 Requests 的功能,提供了无缝切换且简单的接口。无论你是爬虫专家还是新人小白都值得一试,DrissionPage 让我们更简单高效的完成网页自动化任务。
更多的 DrissionPage 值得探索,我也会是在 JavaPub 视频中演示。
注意的是,要遵守网站爬虫规则,合理使用工具,避免违规违法且给网站造成不必要的损害。